You SHALL Parse!
There seems to be a paradox with current state-of-the-art foundational models. They seem to work on some very complex and deep tasks, however, they can struggle on relatively simple tasks. The paradox arises as it is reasonable to assume that some of these simple tasks would be subtasks in the more complex and deep tasks. Therefore, why can a model do these complex tasks but not the simple ones?
My hypothesis is that the models are more proficient at tasks that arise in their chain-of-thought rather than as a prompt. More specifically, the complex tasks are often stated abstractly as a natural language prompt, and so the model is required to parse this into a format that it can handle more naturally. Now that the task is embedded in a natural format, it can more effectively solve the task. On the other hand, simple tasks are often given explicitly to the model in the form of a natural language prompt. The natural language prompt is natural for humans but not necessarily natural for the model, meaning the model ability of the model to solve this task is degraded.
I recently heard an analogy regarding this that I thought was enlightening. Consider a human solving a jig-saw puzzle, they would likely group the pieces according to the context of the image on each piece and then gradually build up the picture by identifying pieces that are nearby in the overall image. However, if we let a computer program learn how to solve this jig-saw puzzle, it would likely just analyse all the shapes of the pieces in detail and then perform a search over all pieces to see which ones should be placed together. For the computer the context of the image on each piece provides no information, whereas for the human it is essential. In each setting, the solver is capitalising on their strengths to solve the problem; the computer is incredibly precise with an abundance of processing power, whereas the human can effectively process and contextualise knowledge. If we tried to impose the strategies of each system onto the other we would likely observe each system making relatively little progress on solving the jig-saw puzzle.
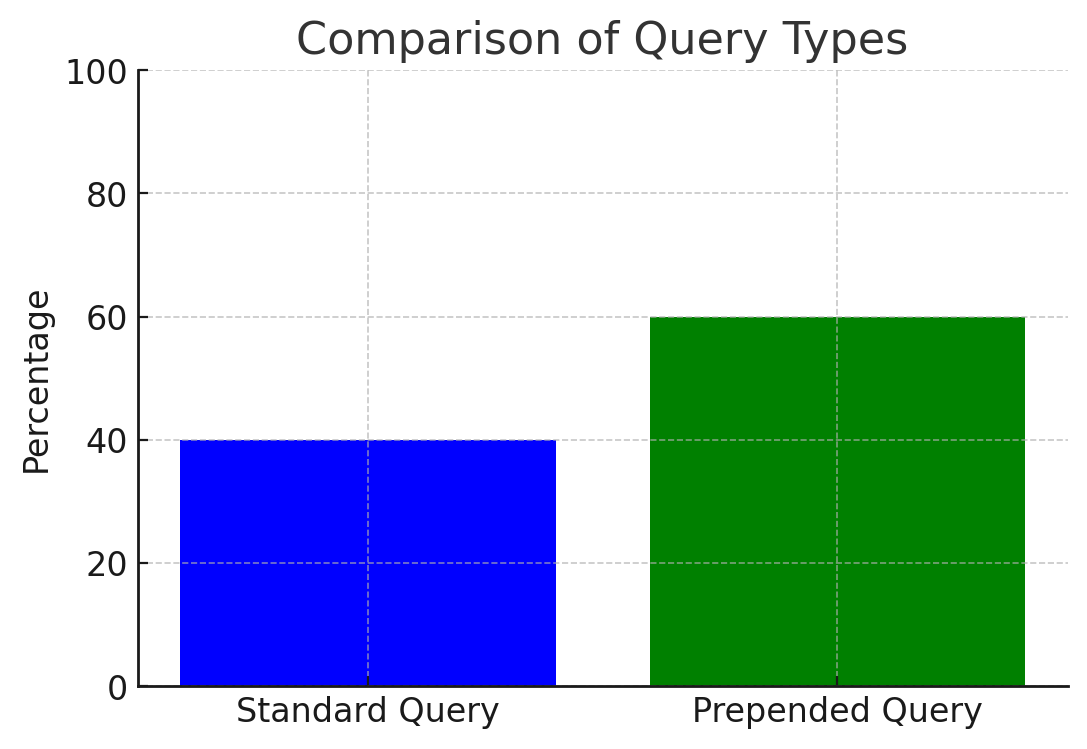
To test these ideas I ran Google’s thinking model “gemini-2.0-flash-thinking-exp-01-21” on the public eval set of SimpleBench, a set of simple multiple choice questions that are overly obfuscated to try and confuse the model. For each query I either passed it directly into the model, or I prepended the question with “compute 1+1” and then asked the model to add this to the result of the SimpleBench query. For instance, if the model responded to the SimpleBench query with C, it would output 5 as 2+3=5. With this prepended prompt, the model is incentivised to parse the different tasks into a natural format before answering them. With this simple modification the performance on the evaluation set went from 40% to 60%, albeit the evaluation set only consists of ten questions so these results should be taken with a grain of salt. However, it is evidence to the claim that allowing the models to parse the question into a format that it is comfortable working in can improve their performance.