Interpretability Beyond Feature Attribution: Quantitative Testing with Concept Activation Vectors (TCAV)
Concept activation vectors introduced are constructed to summarise the representation of a concept in the latent representation of a model. Intuitively they can be thought of as a vector pointing into the space occupied by the activations of the concept. The concept activation vector for a particular concept is obtained from a linear classifier trained to distinguish between activation vectors corresponding to the concept, and the activation vectors corresponding to other concepts.
Concept activation vectors are a supervised approach to extracting features from the learned representations of a neural network. The utilisation of sparse autoencoders on the other hand is an unsupervised approach for feature extraction. Essentially, the idea here is to train an autoencoder model to reconstruct the activation vectors of training samples. By giving the autoencoder a large capacity, one expects that the autoencoder can identify sparse features that fruitful contribute to the reconstruction of the activation vectors. In theory these sparse features would correspond to particular concepts. Indeed this claim has been verified for language transformer models and vision transformer models. We further empirically verify this claim with our own experiments, such that we can investigate the relationship between these features and the concept activation vectors.
Specifically we consider an vision transformer model fine-tuned on the CIFAR10 dataset. We obtain the concept activation vectors from the class-token at each layer and for each of the ten categories in the CIFAR10 dataset. Then we train a sparse autoencoder on the set of activation vectors and investigate the features obtained.
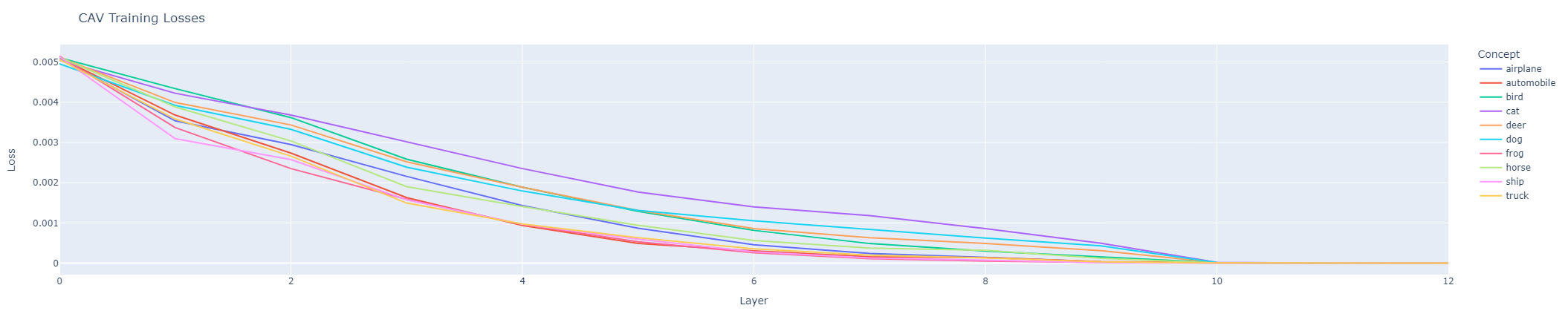
Through the layers, the training loss for the concept activation vector decreases. Suggesting the model is increasingly separating the concepts.
Moreover, we qualitatively see that through the layers the sparse autoencoder obtains more salient features. In layer 3 there is little meaning across the most frequently firing features.

However, in layer 11 we see that there is an interpretable consensus across the images activating the most frequently firing features.

Now using the cosine similarity we can observe which features are most similar to the concept activation vectors, as well as those that are least similar.

Interestingly, we see that feature 1432 is similar to the concept of frog. From the corresponding images we observe that feature 1432 is perhaps encoding for the colour of the frog.
On the other hand, if we investigate the features that are least similar to dog we see that we get features that correspond to the other animals present in the dataset. Suggesting that the model is actively separating animals in its latent space representation since they are similar concepts and so could easily become misclassified by the model.
