Linearity of Relation Decoding in Transformer Language Models
It was shown in [1] that subject-object relationships in transformers are linearly decodable from intermediate layers. More specifically, we consider a prompt containing a subject, say a city, whose next token is an object, say country. For instance, for the 'City in Country' relationships we could have the prompt 'New York City is part of' since the next token is the 'United States'. In this example 'New York City' is the subject and 'United States' is the object. This relationship is said to be linear decodable from an intermediate layer if we can take the subject token activation vector from the intermediate layer, and linearly transform it onto the vocabulary of the model such that the token with the highest values is the corresponding object token.
[1] considers multiple examples of these subject-object prompts and uses the Jacobian of the model between an intermediate layer and the output layer to construct a candidate for this linear relationship. This construction of a linear relationship is referred to as the Linear Relational Embedding (LRE). The faithfulness of the LRE is defined as the proportion of these prompts for which the linear relationship provides the correct completion. The paper concludes that these subject-object relationships are linearly decodable as it observe that many of these candidate relationships are highly faithful.
We can replicate the results of [1] with GPT2.
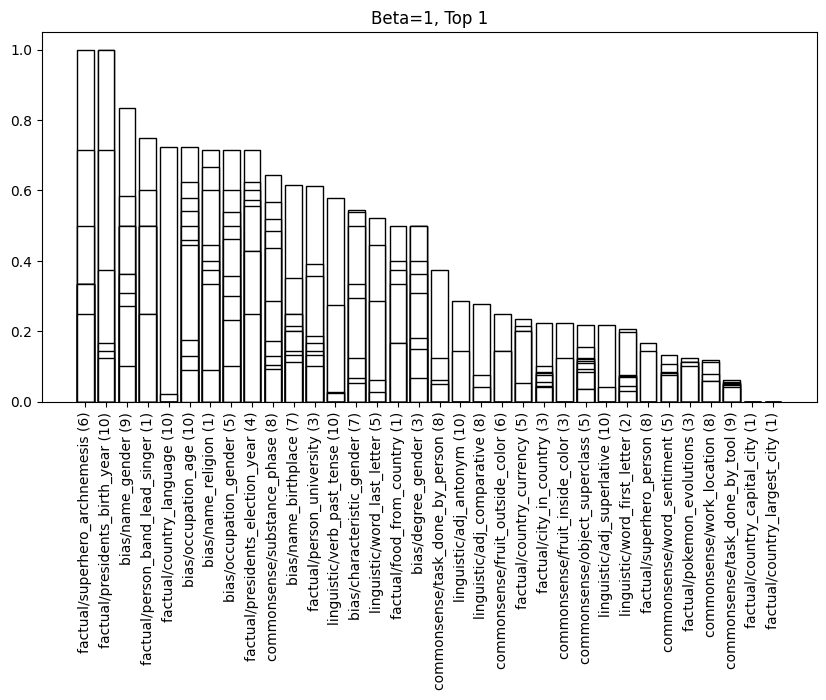
In the above plot, the heigh of the bar gives the faithfulness of the subject-object relationship delineated on the horizontal axis. The bracketed number gives the layer at which the maximum faithfulness scores is attained at, with the lines across each of the bars representing the faithfulness scores for the relationship at other intermediate layers.
Similar to [1] we observe that the faithfulness of the LRE is improved by scaling by a constant greater than one.
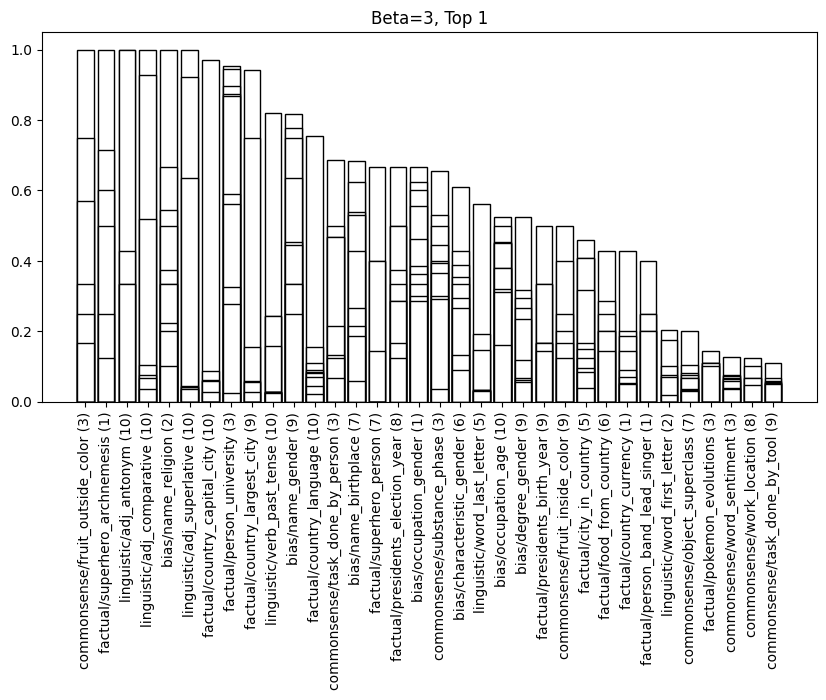
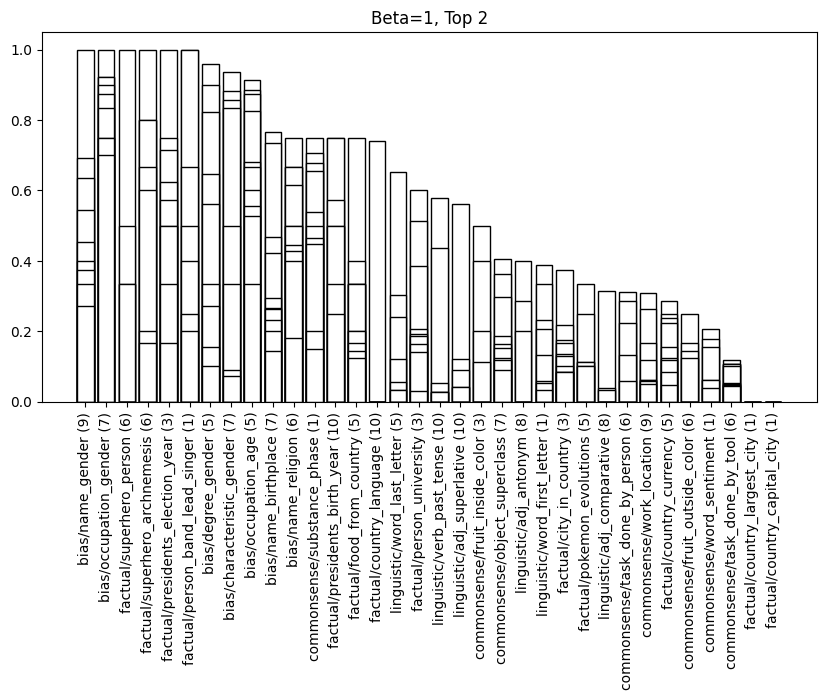
What we see is that the relationship between activations in intermediate layers to the output layer is roughly linear. What's more, if we the relax the definition of faithfulness to allow the target token to appear in the top 2 predicted tokens, faithfulness scores significantly increase. Which provides further evidence for this linear relationship.
References
[1] Hernandez, Evan, Arnab Sen Sharma, Tal Haklay, Kevin Meng, Martin Wattenberg, Jacob Andreas, Yonatan Belinkov, and David Bau. ‘Linearity of Relation Decoding in Transformer Language Models’. arXiv, 15 February 2024. https://doi.org/10.48550/arXiv.2308.09124.